AI — LLM Inference Service
Overview
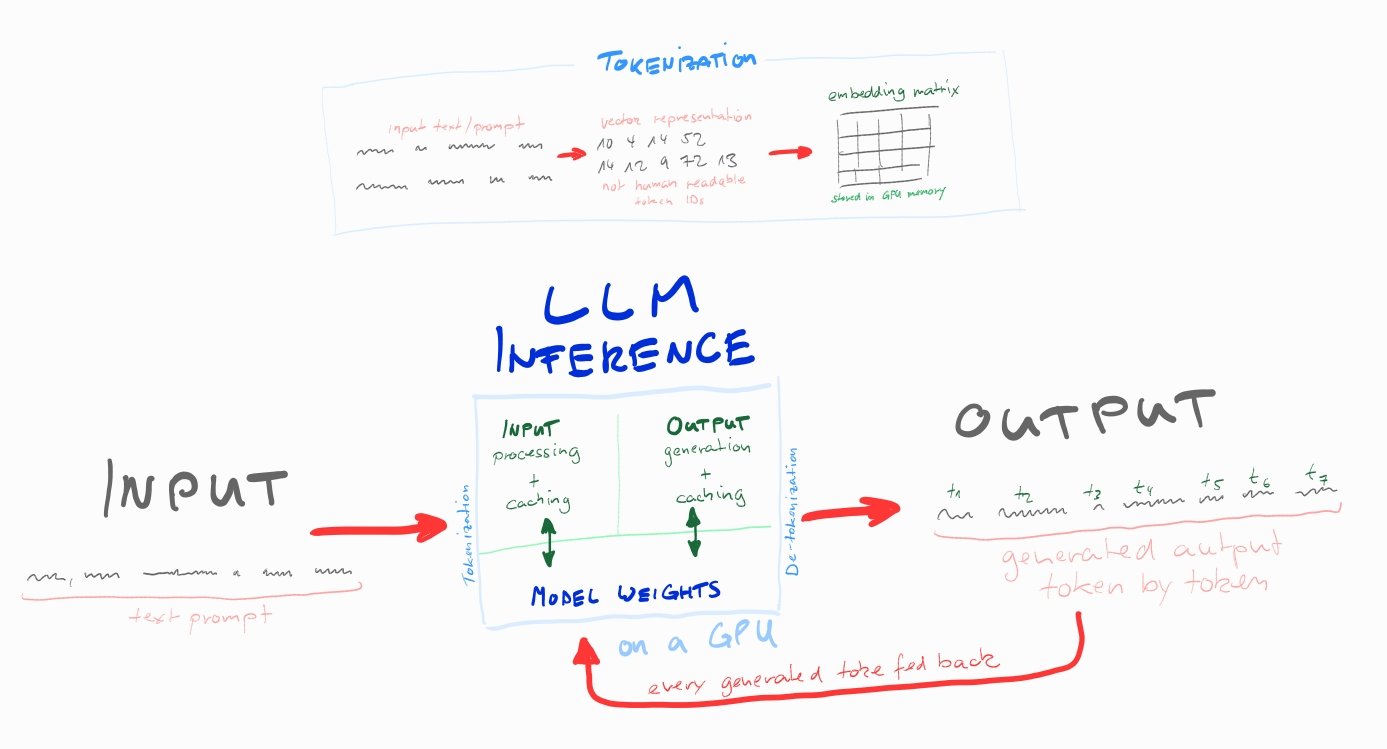
LLM inference1 is the process of performing inference (generate predictions) on a trained LLM
- Large Language Model (LLM)2, pretrained as next-word predictors…
- …take a series of tokens as input
- …generate (predict) subsequent tokens autoregressively
- …until a stopping criteria (typically output length limitation)
- Inference requests vary in terms of number of input and output tokens
- …inference is embarrassingly parallel at the level of requests
Phases
Process involves two phase…
- Prefill — Processing the input
- Process input tokes …intermediate states (keys and values)
- …used to generate the “first” new token
- Resouce intensive …highly parallel matrix-matrix operation
- Each new token depends on all the previous tokens
- Decode — Generate the output
- …generates output tokens autoregressively one at a time
- …needs to know all the previous iterations’ output states (keys and values)
- Less resource intensive (compared to prefill) …matrix-vector operation
Components
Components in an inference engine…
- Batching — Groups multiple queued requests into single execution batch
- …all transfered at once …reduces overhead from individual GPU calls
- …requests share a model …memory cost of weights is spread out
- …improves parallel processing efficiency
- …static batching suboptimal on variable-length output …all wait for the longest
- KV Cache (decoder phase)
- …self-regressive text-generation outputs a token each step
- …each tokens depends on key/value (tensor) of all input + previous tokens
- …use of a dynamic key-value (KV) store …avoid recomputing
- …the KV cache scales linear to the sequence length
Optimization3
- Quantization — Reduce numerical precision
- …reduce memory footprint & accelerates inference over FP32 (full precision)
- Lower precision formats FP16 (half-precision), FP8, FP4 (for edge computing)
- Continuous Batching — Dynamically adds new requests to a running GPU batch
- Server maintains a single batch of requests from various users
- New requests are introduced into the batch from the queue…
- …while new requests are introduced into the batch from the queue
- Small requests can be processed quickly, without waiting for larger requests
- PagedAttention — Sharing of KV cache blocks for requests with similar prompts
- Related to continuous batching …inspired by OS virtual memory
- Fixed size block for KV cache …lookup table to map KV blocks
- Eliminates excessive memory fragmentation in static KV cache allocation
- Speculative Decoding — 2-model workflow to reduce inference latency
- Draft model (smaller/quicker) generates prediction tokens before main model
- Main model validates draft tokens until mismatch …continues generation from there
Models
ONNX4 (Open Neural Network Exchange)
- Open source standard to represnd LLMs in a serialized file
Memory
LLM memory (VRAM) requirements defeind by…
- Model Parameters (weights)
- e.g. Llama 2 7B * sizeof(FP16) ~= 14GB memory
- KV cache occupied by the self-attention tensors
- …allocates dedicated memory for each request
Architecture
| Component | Description |
|---|---|
| UI | Front-end for user input (web/mobile) |
| API Gateway | Access point ot the backend service |
| Load Balancer | Distrubute incoming request from the API gateway |
| Inference Server | Process input data via LLM and generate output |
| Model Repository | Stores trained LLMs |
| Pre Processing | Prepare input for the inference model |
| Post Precessing | Format output for the user |
| Database | Store user interactions, model metadata |
Inference Server
Inference Server — Acts as bridge between LLM and users inference requests
Inference Engine — Executes traind LLM efficiently on hardware
- Query queue — Manages incoming requests in a queue
- …to avoid overwhelming the model
- …group multiple requests together into a batch
- Model execution — Runs the LLM model
- …allocates required hardware (typically a GPU)
- …trained models in
.ptPyTorch or.tf2TensorFlow format - …model takes the batched input and generates output tokens
- Query repsonse — Gathers model outputs
- …splits into individual responses for each original request
Related projects:
Load Balancing
Orchestration of multiple LLM services…
- Llumnix11
Metrics
Performance metrics:
- TTFT (Time to First Token)
- Responsiveness from the user perspective
- Time until a model begins to generate output
- Responsiveness from the user perspective
- TPOT (Time per Output Token) aka ITL (Inter Token Latency)
- Average time to generate each subsequent token
- Overall fluidity go generation experience by the user
- Total Time to Generation
- Measures total time to process input and generate all tokens
- ISL (Input Sequence Length)
- OSL (Output Sequence Length)
- Throughput (tokens per second)
- Total output generation capacity
- Measure for hardware utilizations related to output
Benchmarking needs to be aligned with workload profile…
- Low-concurrency …few simulations users …evaluate baseline performance
- High-concurrency …many simultaneous users …evaluate throughput scaling
- Variable-length workloads …different prompt length to stress memory & scheduling
Maximum Batch Weight12 — Maximum allowed ‘volume’ of the batch…
- …total number input and output tokens of all requests processed
- …larger memory space …the more requests can be processed in parallel
- …improves the throughput of the inference service
Questions
What is the difference between LLM training and inference?
- Training — Teach a model to recognize patterns …make accurate predictions
- …computationally intensive …requires expensive GPU/TPU clusters
- …initial training cost high …one-time expense to create the model
- …periodical retraining required to update/improve the model
- Inference — Apply a trained model to make predictions
- …continuously …responds in real-time to user input
- …smaller resource requirements then training
- …resource requirements cumulative with the number of user requests
What is the difference between serverless vs. self-hosted LLM inference?
- Serverless — Use a provider like OpenAI13 , Antropic14
- As simples as: Send prompt …get response …pay by the token
- Providers typically charge based on the number of tokens processed
- Benefits …no infrastructure required, rapid prototyping, hardware abstraction
- Potential limits …cost, latency, customization, privacy, compliance
- Self-hosted — On premiss deployment of an LLM inference service
- Requires hardware infrastucture and deployment/operations expertise
- Benefits …full control over models, deployment, costs, privacy, complianze
What is the difference between proprietary and open-source models?
- Proprietary — GPT-4 (OpenAI), Claude (Antropic)
- …developed by private companies
- …often with state-of-the-art performance
- …usually through API calls or cloud services
- Open Source — DeepSeek-R1, Llama 4, Mistral
- …publicly available code and weights
- …community-driven improvements
- …download …runs on local infrastucture
- LMArena15 comparison of proprietary and open-source models
References
Footnotes
LLM Inference Handbook
https://bentoml.com/llm↩︎Hugging Face Models
https://huggingface.co/models↩︎Mastering LLM Techniques: Inference Optimization, NVIDIA (2025/09/24)
https://developer.nvidia.com/blog/mastering-llm-techniques-inference-optimization/↩︎ONNX Runtime Documentation
https://onnxruntime.ai/docs/↩︎vLLM, GitHub
https://github.com/vllm-project/vllm↩︎TensorRT-LLM, NVIDIA, GitHub
https://github.com/NVIDIA/TensorRT-LLM↩︎Hugging Face TGI, GitHub
https://github.com/huggingface/text-generation-inference↩︎SGLand, GitHub
https://github.com/sgl-project/sglang↩︎DeepSpeed, GitHub
https://github.com/deepspeedai/DeepSpeed↩︎Trition (NVIDIA), GitHub
https://github.com/triton-inference-server/server↩︎Llumnix, Alibaba, GitHub
https://github.com/AlibabaPAI/llumnix↩︎LLM-Pilot: Characterize and Optimize Performance of your LLM Inference Services
https://arxiv.org/html/2410.02425↩︎OpenAI
https://openai.com↩︎Antropic
https://www.anthropic.com↩︎LMArena
https://lmarena.ai/leaderboard↩︎